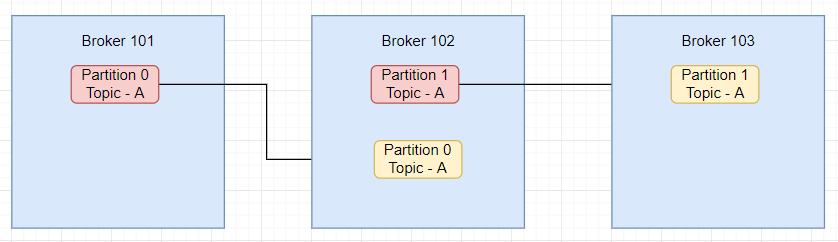
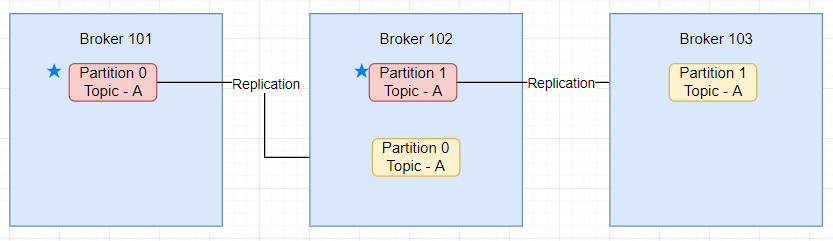
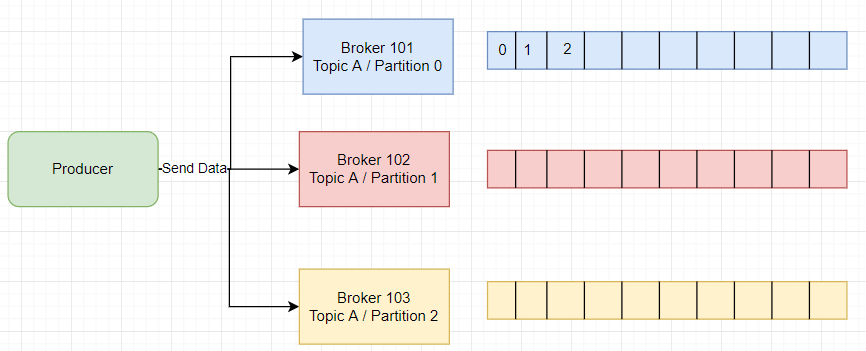
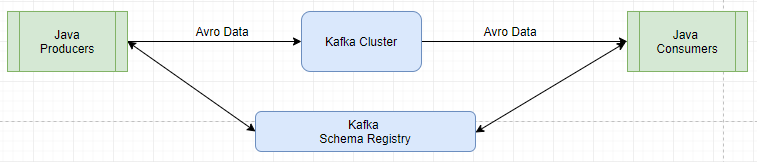
VS Code Setup for Golang Programming

As a Go developer, having the right programming environment can significantly boost your productivity. Visual Studio Code has become the go-to editor for many Golang developers, thanks to its excellent extension ecosystem and customizability. In this guide, I'll walk you through creating the perfect VS Code setup for Go development.
Table of Contents
- Installing Prerequisites
- Essential Extensions
- Advanced Configuration
- Productivity Tips and Tricks
- Debugging Setup
- Theme and UI Customization
Installing Prerequisites
Before we dive into VS Code configuration, ensure you have:
- The latest version of Go installed (1.22+ recommended)
- Git for version control
- Visual Studio Code
- Make (optional but recommended for build automation)
Essential Extensions
Let's start with the must-have extensions for Go development:
-
Go (ms-vscode.go)
- Official Go extension
- Provides language support, debugging, and testing features
- Install by pressing
Cmd+P(Mac) orCtrl+P(Windows/Linux) and typing:ext install ms-vscode.go
-
Go Test Explorer
- Visual test runner for Go
- Makes testing more intuitive and visual
-
Error Lens
- Inline error highlighting
- Better error visibility without hovering
-
GitLens
- Enhanced Git integration
- Great for team collaboration
Advanced Configuration
Here's an optimized settings.json configuration for Go development:
{
"go.toolsManagement.autoUpdate": true,
"go.useLanguageServer": true,
"go.addTags": {
"tags": "json",
"options": "json=omitempty",
"promptForTags": false,
"transform": "snakecase",
},
"gopls": {
"formatting.gofumpt": true,
"usePlaceholders": true,
"ui.semanticTokens": true,
"staticcheck": false, // Enable if it's now better optimized
},
"go.lintTool": "golangci-lint",
"go.lintFlags": [
"--fast",
"--timeout",
"5m",
"--fix"
],
// disable test caching, race and show coverage (in sync with makefile)
"go.testFlags": [
"-cover",
"-race",
"-count=1",
"-v",
"-s",
"-benchtime=5s",
"-timeout=5m"
],
"go.enableCodeLens": {
"runtest": true,
},
// Go-specific editor settings
"[go]": {
"editor.insertSpaces": false,
"editor.formatOnSave": true,
"editor.formatOnSaveMode": "file",
"editor.stickyScroll.enabled": true, // Better navigation for long files
"editor.codeActionsOnSave": {
"source.organizeImports": "always",
"source.fixAll": "always"
},
},
// Enhanced inlay hints
"go.inlayHints.compositeLiteralFields": true,
"go.inlayHints.compositeLiteralTypes": true,
"go.inlayHints.functionTypeParameters": true,
"go.inlayHints.parameterNames": true,
"go.inlayHints.rangeVariableTypes": true,
"go.inlayHints.constantValues": true,
// Security checks
"go.diagnostic.vulncheck": "Imports",
"go.toolsEnvVars": {
"GOFLAGS": "-buildvcs=false" // Better performance for large repos
},
}
Productivity Tips and Tricks
1. Keyboard Shortcuts
Essential shortcuts for Go development:
F12: Go to definitionAlt+F12: Peek definitionShift+Alt+F12: Find all referencesF2: Rename symbolCtrl+Shift+P: Command palette (use for Go commands)
2. Snippets
Create custom snippets for common Go patterns. Here's an example snippet for a test function:
{
"Test function": {
"prefix": "test",
"body": [
"func Test${1:Name}(t *testing.T) {",
" tests := []struct{",
" name string",
" input ${2:type}",
" want ${3:type}",
" }{",
" {",
" name: \"${4:test case}\",",
" input: ${5:value},",
" want: ${6:value},",
" },",
" }",
"",
" for _, tt := range tests {",
" t.Run(tt.name, func(t *testing.T) {",
" got := ${7:function}(tt.input)",
" if got != tt.want {",
" t.Errorf(\"got %v, want %v\", got, tt.want)",
" }",
" })",
" }",
"}"
],
"description": "Create a new test function with table-driven tests"
}
}
3. Task Automation
Create a tasks.json for common operations:
{
"version": "2.0.0",
"tasks": [
{
"label": "go: build",
"type": "shell",
"command": "go build -v ./...",
"group": {
"kind": "build",
"isDefault": true
}
},
{
"label": "go: test",
"type": "shell",
"command": "go test -v -cover ./...",
"group": {
"kind": "test",
"isDefault": true
}
}
]
}
Debugging Setup
Configure launch.json for debugging:
{
"version": "0.2.0",
"configurations": [
{
"name": "Launch Package",
"type": "go",
"request": "launch",
"mode": "auto",
"program": "${fileDirname}"
},
{
"name": "Attach to Process",
"type": "go",
"request": "attach",
"mode": "local",
"processId": "${command:pickProcess}"
}
]
}
Theme and UI Customization
For optimal Go development, I recommend:
- Theme: One Dark Pro or GitHub Theme
- Font: JetBrains Mono or Fira Code with ligatures
- Icon Theme: Material Icon Theme
- Editor: Line cursor, smooth blinking, and 4-space tabs
- Window: Zoom level 0.5 for better readability
- Rulers: Set at 88 and 120 columns for code alignment
- Minimap: Disable for better performance
- Inlay Hints: Font size 14 for better visibility
- Tree Indent: Set to 20 for better file navigation
- Auto Indent: Full for consistent code formatting
Apply these settings in your configuration:
{
"window.zoomLevel": 0.5,
"workbench.iconTheme": "material-icon-theme",
"workbench.tree.indent": 20,
"editor.cursorStyle": "line",
"editor.cursorBlinking": "smooth",
"editor.fontSize": 14,
"editor.fontVariations": false,
"editor.inlayHints.fontSize": 14,
"editor.tabSize": 4,
"editor.insertSpaces": true,
"editor.autoIndent": "full",
"editor.fontFamily": "'Fira Code'",
"editor.fontLigatures": true,
"editor.minimap.enabled": false,
"editor.rulers": [88,120],
}
Conclusion
This setup provides a powerful, efficient, and visually appealing environment for Go development. Remember to regularly update your VS Code and extensions to get the latest features and improvements.
The beauty of VS Code lies in its customizability – feel free to modify these settings based on your preferences and workflow. The key is finding the right balance between functionality and simplicity that works best for you.
Happy coding! 🚀
Did you find this guide helpful? Follow me for more development tips and tricks!